In addition to not being a database, Excel is also not a statistics package. If you are going to do anything advanced, I highly recommend R. The programming language, not the John-Cleese-played Q replacement in The World is not Enough and Die Another Day.

Cheer up! Yes, it’s a lesser part in lesser Bond movies.
You, John Cleese, are still an international treasure.
Anyway, stats in Excel. We’ll start with correlations, as they can give us some insight into blog and Facebook traffic and interactions.
Wait, you argue – Facebook is not direct marketing. First, yes, you are correct. Second, no, you are wrong; there is a way that you can use Facebook as a direct marketer. I’ll talk about this more when I do a whole social media week (don’t worry, folks, I promise to spend time deflating the hype and hopefully producing things you can print out and get to board members and say “See? Let’s put money in places where it will make money!”). Third, because Facebook has limited value (but not zero) as a direct marketing vehicle, you can test things on there to see how they resonate with your audience. Granted, your Facebook audience and direct mail audience will probably be fairly dissimilar, but your online audience is probably similar to your Facebook audience. And what you are looking for is what makes compelling online content for you. So this is a way to make Facebook your testing ground before you put it on to a real platform (i.e., your Web site, your emails).
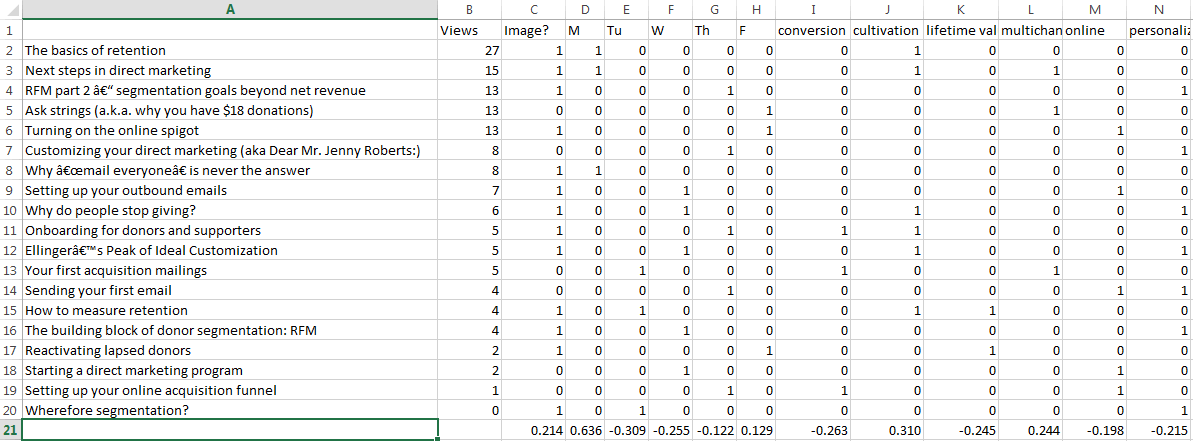
I’m going to demonstrate this on this blog’s stats because I have the data available. However, I’ve also done this with Facebook posts very successful. The prep work you will have to do for either blog posts or Facebook posts is to record your outcomes (view, likes, shares, and/or comments), to code the subject matter of each post, and to put in any other variables like day of the week that may be relevant. Here’s my version of this:

I have my blog posts on the left and the various factors on the right (and there are more tags, but I need to cut it off at some point to display it. Yes, I have a blog post that has zero views. If you would like to break the seal on a blog post about why we do segmentation, it’s here; I’m sure it would appreciate a visit.
I then went through this and deleted tags that only applied to a single post. Then I ran a correlation for each individual variable to page views. The correlation function looks like
=CORREL($B2:$B20,I2:I20)
And is expressed from 1 to -1.

Here’s what that looks like. Let’s look at the days of the week first, because there appears to be an effect here — Monday content has been king, with a strong correlation to page views. It will be interesting going forward to see in the long term whether that is the nature of the content (I’ve been trying to put introduction content on Mondays and get progressively more involved throughout the week) or that people are more interested in reading blog posts on Mondays. Nevertheless, I can probably do a better job of setting up the rest of the week as must-see content, since Tuesday, Wednesday, and Thursday are all a bit negative.
Images tend to correlate well to views as well, probably because they show better in social media. I’d been noticing this from just a glance as well, so you will probably be seeing more images here in the weeks to come. They will also be less boring images, since some of the lower performers were images of equations and Excel sheets. It is not coincidence that the tallest Python led this blog post.
And it looks like cultivation and multichannel efforts are winning while conversion, lifetime value, and personalization are not as strong, with negative correlations to page views. I won’t be acting on this immediately, but keeping an eye on it. And I do have a multichannel week planned in the near future, so we’ll be able to test whether that’s an artifact in the data.
However, you might notice that the reason cultivation is ranked so highly is that it is in the two top performing posts, which are Monday posts. Is it the topic or the day that made those strong? For this, you need regression.
Normally, you wouldn’t do this after only 20 blog posts. We are not going to be able to draw any statistically significant conclusions, but I do want to show you how it’s done.
- Go to Data > Data Analysis > Regression
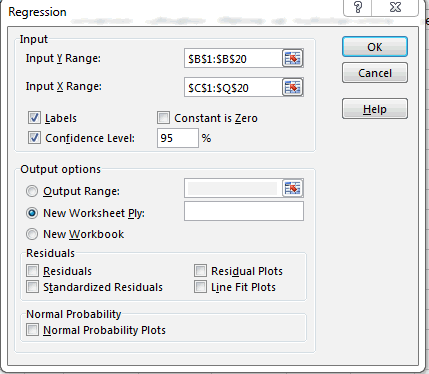
- Select the range from your outcome variable as your Y range and the range of the independent variables you want to test in the X range like so:
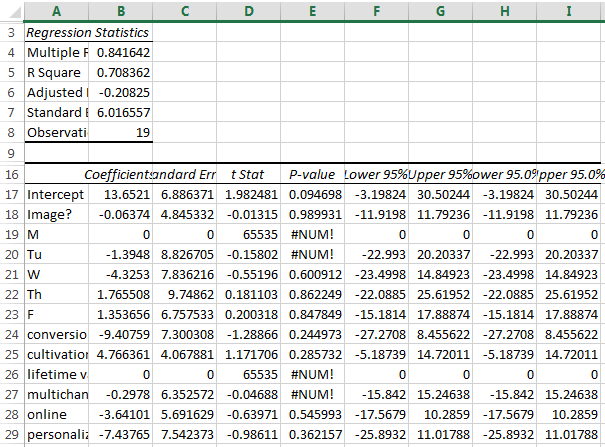
- Hit OK. You’ll get something that looks like this. In my case, it’s a really, really bad regression:
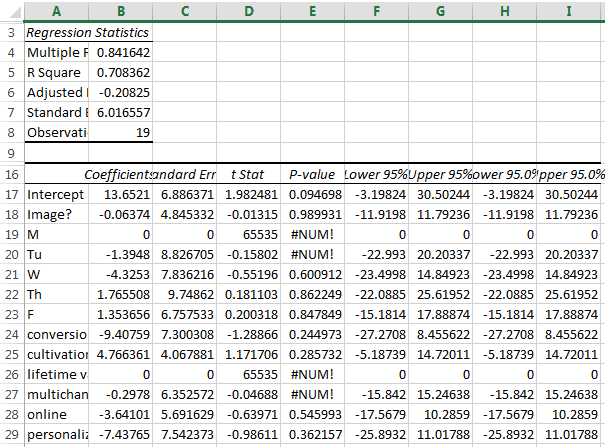
Yuck. The things you would normally be looking for are:
- in R-squared, you are looking for as close to 1 as possible. One would mean your model is totally predictive. Zero means it predicts nothing at all.
- In P-value per variable, you are looking for less than .05. That would show if there is a statistically significant relationship between any of the variables and your output. In this case, there isn’t and we can pretty much throw out the whole thing.
- If there is a relationship, you want to look at the coefficient for two things:
- Is it positive or negative? Positive is good things; negative is bad things.
- How big is the relationship? In this one, if these were significant, it would be a bad idea to post about personalization again, as posting about it reducing views by 7. But it isn’t significant, so I’m not yet worried.
Hope this helps you with the stats side of Excel. Tune in next week, when we look at some of the things that Excel is actually good at.